让 GitHub 仓库的代码占比统计中包含 Markdown 文件
背景
对于 Nólëbase 这样的使用 Git 作为版本管理和协作的知识库和其他众多的文档站点(比如 Kubernetes 文档站 kubernetes/website),默认配置的情况下,GitHub 可能会把仓库内的代码占比展示为下面这样:

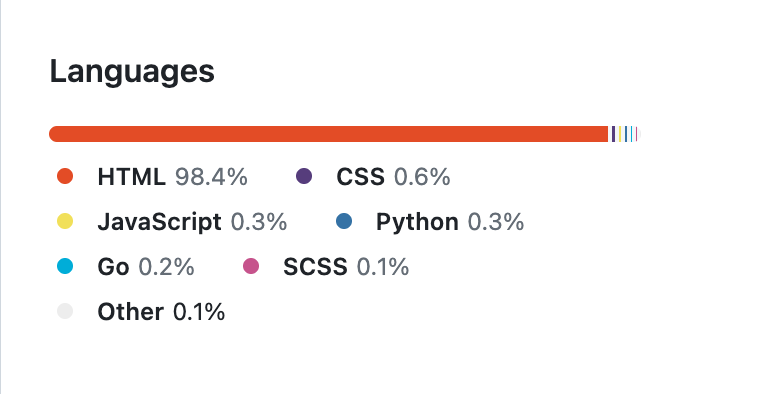
可以观察到对于充斥着一定程度的 HTML 模板的仓库而言,即便实际仓库内包含的主要是 Markdown 文件,GitHub 也依然会把大量的 HTML 统计为占比最多的文件。
这是因为 GitHub
但殊不知,GitHub 其实是支持对 Markdown 文件类型进行统计计数的,只需要一点点额外的配置就能达到这样的效果:

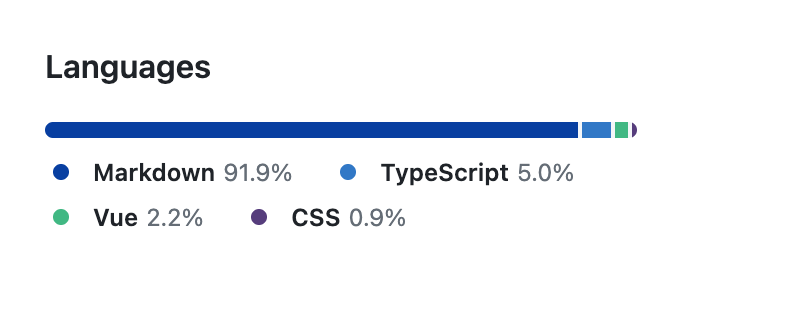
上图是 Nólëbase 的主要仓库 nolebase/nolebase 的代码占比统计信息,可以看到在调整配置之后,Nólëbase 中的巨量 Markdown 文件就能被统计到占比中了。
如何实现
想要配置这样的功能其实很简单,在这一切背后,GitHub 使用了一个名为 Linguist 的组件来探测文件类型[1],这样的配置是通过在名为 .gitattributes 文件中实现的,你需要在根目录中创建一个名为
.gitattributes的文件并且填充下面的内容
*.md linguist-vendored=false
*.md linguist-generated=false
*.md linguist-documentation=false
*.md linguist-detectable=true就能实现对仓库内所有 .md 为拓展名结尾(Markdown)文件的配置。
这些配置选项具有这样的含义:
linguist-vendored=false表示匹配到的文件不是外部代码,如果配置为true,则将会被在占比统计中排除linguist-generated=false表示匹配到的文件不是生成的代码,如果配置为true,则不仅会被在占比统计中排除,也会在 diff 中被排除linguist-documentation=false表示匹配到的文件不是文档类型的文件,如果配置为true,则将会被在占比统计中排除linguist-detectable=true表示强制匹配到的文件纳入到占比统计中,即便文件是prose(也就是 Linguist 认为的 Markdown 类型的文件)和data(也就是 Linguist 认为的 SQL 这样的类型的文件)[2]
详细的配置选项介绍可以在 Overrides - Linguist supports a number of different custom override strategies for language definitions and file paths. · github-linguist/linguist 查阅到。
当然你也可以使用和 .gitignore 一样的 glob 语法来匹配目录:
docs/*.md linguist-vendored=false
docs/*.md linguist-generated=false
docs/*.md linguist-documentation=false
docs/*.md linguist-detectable=true接下来你可以通过
git check-attr -a <文件路径>这样的命令来测试文件所匹配得到的 attribute,就像这样:
❯ git check-attr -a README.md
README.md: linguist-vendored: false
README.md: linguist-generated: false
README.md: linguist-documentation: false
README.md: linguist-detectable: true参考资料
- Markdown language is not detected · Issue #3964 · github-linguist/linguist
- Add markdown as language · Issue #5951 · github-linguist/linguist
- Overrides - Linguist supports a number of different custom override strategies for language definitions and file paths. · github-linguist/linguist
延伸阅读
- How to Get Github to Recognize a Pure Markdown Repo
- 详细的 Linguist 配置选项:Overrides - Linguist supports a number of different custom override strategies for language definitions and file paths. · github-linguist/linguist
- 关于什么是
.gitattributes文件:Git - gitattributes Documentation
贡献者
 絢香猫
絢香猫页面历史
在 GitHub 的讨论 Add markdown code portion counting 中,作者 @airtower-luna 介绍了 GitHub 所使用的 Linguist 的文件类型探测模块的配置文档。 ↩︎
在 Linguist 的 Issue #3964 的评论中提到的:「data (e.g. SQL) or prose (e.g. Markdown)」 ↩︎